Blog Feed
Upwell’s unique model of “community management”
One of the goals of Upwell was to empower the influential voices in Team Ocean to create and share content that would increase attention to the crisis the ocean is facing. While much of our time was devoted to creative campaigning and all-consuming research projects to meet that goal, there’s one important element we talked less about: community management.
My job was as much about communicating within the network of ocean influencers as it was about the ideas they communicated about with the world. Without a strong network, our campaigns would be like a fancy car with no fuel - they’d look nice, but they’d go nowhere.
In our pilot report of 2013, we detailed how we built our community from the ground up (page 54). Here’s just a selection of the community building activities we detailed in that report:
We attended conferences like the Blue Ocean Film Festival, Oceans in a High CO2 World, and Science Online. We provided in-depth feedback and data to groups like The Ocean Project and Conservation International on efforts like World Oceans Day and the Ocean Health Index. We sent our most loyal Tide Report subscribers postcards on a weekly basis, thanking them for being part of Team Ocean. We conversed with our peers on Twitter and retweeted their content when we couldn’t feature it in a Tide Report. We also did some strategic work to better connect the lingerers and lurkers in our network. We analyzed our Tide Report subscriber list against our Twitter followers and Facebook fans to understand how to more deeply engage people that were only aware of some of our activities.
When we asked people to sign up and join us, it wasn’t a one-time thing. Our welcome email, sent to new subscribers of the Tide Report, told them we were asking them to make us a commitment:
Our goal is to increase the number of social mentions about the ocean issues we all care about. To do that, we rely on you.
We know you care about the ocean, but it's not always easy to find great content to share. That's where we come in. We find, create, and package awesome stuff (videos, images, blog posts, and more), share it with you in the Tide Report, and in each issue, we ask you to spread them via your social channels (your personal and your organizational ones!)
At the root of our community building and managing philosophy is a commitment to provide value. We knew the people in our network wouldn’t amplify what we suggested unless they felt they were getting something from us. We did this by connecting people with each other, giving away our conversational research, and acting as a free PR service for captivating ocean campaigns.
Reciprocity is the currency of the internet. Whatever we received or found we then shared and amplified. This turn-up-the-volume effort helped many ocean influencers connect with audiences who might have missed them. The Tide Report, Upwell’s blog and social media channels, topic-specific webinars, plus staff speaking engagements, guest blog posts and project consulting have provided channels for delivering this value to a diverse audience of time-starved ocean activists.
Our method of influencer community management has been a hybrid of modern digital PR, offline community organizing, and online community management. One useful lens for our practice is this: we had a hub-and-spoke model, in which information flowed in, was filtered, and reflected back out. We weren’t placing ourselves at the hub in order to gain power or influence for ourselves, but rather to increase the power and influence of our peers.

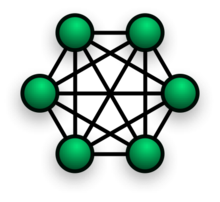
Hub-and-spoke network or fully connected mesh network? A little of both.
Rachel thought of this as a concierge service for the nascent ocean movement, offering tailored tips and services to ensure a successful visit to the internet. We prioritized driving traffic and attention to our community members, rather than toward ourselves (which gave us lots of metrics-related headaches). We aspired to a fully connected mesh style network, wanting the members of the network to be visible to each other. What made our model unique is that we reflected our community back to itself, while adding a layer of insight. We did this on a regular basis, but we also had focused moments like the Sharkinar where we intentionally increased the size, impact and reach of a specific issue community.
These were some of the methods that defined our influencer community management model:

Targeted recruitment
As mentioned above, Upwell attended conferences and meetings and we asked people to join our network in person. Many of these people were identified and specifically targeted. Through our conversational research, we also identified online influencers around key ocean topics, and reached out to them over Twitter and email to ask them to sign up for the Tide Report and join our webinars. Our recruitment methods went into high gear around events like our #Acidinar and our #Sharkinar. We wanted to make sure the right people, who could significantly influence online conversation, would be on the phone.
Data services
A core part of Upwell’s work was around conversational data analytics. We had access to social data scraping tools that would have been prohibitively expensive for many organizations to access on their own. By taking the lens of movement-level metrics we were able to provide an entirely new service to a diverse community. Our analysis was sometimes shared in little bits, via our blog and the Tide Report, and sometimes shared in large chunks like our pilot report and our State of the Online Conversation reports about Overfishing and Ocean Acidification.
Content filtering
We received far more tips via our tips email line than we could possibly promote. And often, as I described in my blog post about creating shareable content, the tips we received had some, but not all the necessary elements to generate conversation. We often acted as a filter, receiving all the awesome work from Team Ocean, picking and choosing what to amplify (based on transparent curation criteria), investing creative resources to repackage when necessary, and reflecting back out to the community.
Holding up a mirror
This is the part of our community management that may feel the most familiar. By retweeting and sharing the content of our community, sharing job postings and calendar events, thanking individuals by name, and including the accomplishments of peers in our Tide Report, we simply kept our community members on each other’s radar. We held up a mirror so that our community members saw each other and understood how they all fit together as part of a larger team. As part of this friendly mirror responsibility, we’d also (metaphorically) tell influencers if they had spinach in their teeth, AKA a gentle heads up that if we saw an influencer sharing old/ inaccurate/debunked links.
What made it possible
As part of our work in documenting our community management practice, Rachel and I had a good long discussion yesterday about what familiar network metaphor best fits how we’ve approached this work at Upwell. It resulted in the inclusion of the hub-and-spoke and mesh network references above. But ultimately, we couldn’t quite settle on just one.
We’ve relied on being the hub, where people send their hot tips and look to when they want to know what to share. But we’ve wanted to do it relatively invisibly, in order to not steal any spotlight from our friends and oceany colleagues.
What’s made it possible is all of the individual relationships and the people who trusted us even if we didn’t have 100K followers on Twitter and weren’t the ones being interviewed about breaking news. That’s because our network was an amalgamation of friendships and close working relationships, and we are grateful to the loyalty of every single person. Thank you forever for your trust, and for sharing both your amazing ocean news and the attention of your followers.
Top six ways to ensure your conservation content gets shared
In three years at Upwell, we’ve played a lot with content. We’ve remixed, rewritten, repackaged, curated, and amplified. We’ve looked for the most shareable content - the most captivating videos, the powerful images, the inspirational quotes - and tried to get more people to see and share. We’ve also looked for the content that was important and groundbreaking, but not yet shareable - the scientific studies, the policy papers - and tried to find ways to make it shareable.
Over the years, we’ve told you what we've learned about how to package your content so it’s the most shareable. Here are our top tips.

1. Always appeal to high energy emotions
Videos that merely educate are less shareable than those that tell a story that will captivate. There are a wide range of emotions you can appeal to, from awe to humor to fear to schadenfreude. When crafting your content, whether it’s a blog post, an image, or a video, think about what emotion you are trying to inspire.
Last year’s controversial Facebook experiment, which manipulated the emotions of Facebook users, showed that the emotions of your peers on social media influence your own. While we hate to use the findings of an experiment that toyed with basic notions of privacy, we did take away that if we want to inspire hope for the ocean, we should communicate hope. And, indeed, we have read that high energy emotions (like awe and excitement) are more likely to be shared than low energy emotions (like sadness or contentment), and positive emotions are more engaging on social media than negative emotions.
In our research into the online conversation about California’s marine protected areas (MPAs), we learned that social media posts that conveyed love and a call to protect MPAs were more engaging than those that merely educated audiences about MPAs. This is why we’ve invested so heavily at Upwell to promote the theme of #oceanoptimism, and we hope Team Ocean will carry this on.
2. Make sure your visuals not only tell a story, but communicate a value
By now, we all know that we should be sharing images or video with almost everything we post on social media. The goal of an image paired with your content is to visually convey a story, and importantly to do it in one highly-sharable glance, so that people are encouraged to click and learn more. We have found at Upwell that images that show humans interacting with the ocean help tell a story better than those that merely depict ocean creatures.
A story that conveys a value is even more shareable. (Think: not just “this fisherman is battling ocean acidification” but “this fisherman’s battle with ocean acidification shows us the consequences of our actions.”). Words superimposed over an image help convey a story and value, but the image chosen is just as important: it also ideally conveys essential elements of the narrative frame we’re strategically spreading. The postures, the background, and the demographics of those persons depicted all heavily set the story for the words we place on the picture.
People share because they wish to associate their personal (or brand) identity with the narrative depicted, and to tell their peers and friends that they think it’s a story worth listening to. Climate Access’s Ten Steps to Improving Energy Efficiency Imagery include great lessons for imagery in social media, even for those who are not focused on energy efficiency in their work.

This image, shared hundreds of times on Facebook, communicated not just information, but a value.
3. Provide shareable content with scientific reports
It’s a story we’ve all heard before: a scientific paper comes out and the media covers it in a way that the paper’s authors disapprove of. Either the findings are skewed or misreported, or the visuals paired with media coverage don’t tell the whole story. Most often, this isn’t due to a lack of integrity on the part of the journalist - instead, it is because the “so what” isn’t communicated clearly in the press release.
It is journalists’ jobs to find that “so what,” and if you don’t tell them what it is, they will try to find it on their own. Additionally, the graphics and photographs shared with scientific papers are often not high resolution or don’t immediately communicate the top findings, so journalists often turn toward stock imagery to pair with their articles. Check out Compass Online’s tips for sharing your science to learn more about how to arm journalists to explain your research correctly.
4. Adapt to the limits (and preferences) of your social media platforms
Even if your content appeals to emotions and values and it includes captivating imagery, if it doesn’t load correctly on Facebook, or if your image is cut off on Twitter, you’re missing a huge opportunity. Think: how many videos have you watched because they’re right in front of you, versus videos that you had to click two or three times to view? If you are sharing a video on Facebook, use Facebook’s proprietary video platform, as it plays automatically in the feed. If you’re sharing a video on Twitter, share it using YouTube because viewers won’t need to leave Twitter to watch it. Utilize Facebook’s og: tags to define what text and what image show up when someone shares a link to a page on your website. If you have a viewpoint to express, think about where you can share it that will encourage the most attention - it may not be your own blog, but instead might be one that has a highly engaged audience built in.
These steps take extra time (e.g., uploading your video to multiple platforms, and combining analytics for all platforms during reporting), but they lead to much higher engagement in total, and ultimately, more impact. If you use your own proprietary video platform, unfortunately your videos will not be playable on major social media networks. Think about how you can reduce the number of clicks between your audience and your content to one. Even two or three clicks can prevent you from getting your message across.
5. Unbranded is best, but less branding will do
People don’t want to share advertisements - they want to share content. Studies have shown that “Millennials,” the internet-native generation, feel more aligned with issues and causes than they do with organizations and brands. We’ve seen time and again that it isn’t necessary to put your logo on every image you create and share on Facebook, particularly if it is attached to a piece of content that communicates your value. In fact, unbranded content has the potential to be shared more broadly and ultimately generate more traffic toward the content you are sharing and more support for your cause. While you may be required to include your logo on public communications, use it only to support your message, and don’t lean on your brand to carry the message. Check out 350.org’s Facebook page for some great examples of unbranded and minimally branded content.
6. Simplify, simplify simplify.
When Upwell was creating images to share in our campaigns, we’d often go through ten versions before settling on one. Most often, we were trying to find a way to reduce the amount of text on the image, but we were also looking for the right image - the one that conveyed the right tone and message in the clearest way. We were also in constant pursuit of shorter, more digestible videos we could share, like MBARI’s anglerfish video that went viral late last year.
As passionate communicators, we want our audiences to know everything about an issue, to understand it inside and out. But when we create content that we want people to share, we can’t overburden that content with information. Choose one captivating idea, one opinion, one quote, or one statistic or fact, and lead with that. If you can “hook” people with that one idea, they will be excited to learn more. Want to know more about how to do this? Check out this story on Beth Kanter’s blog about an image that was worth 25,000 shares.
For more on Upwell’s approach to content packaging, especially as it relates to ocean content, check out the case studies beginning on page 61 of our Pilot Report.
While Upwell is closing this month, we know that the lessons from our work have been integrated into the outreach of Team Ocean. Follow Team Ocean on Twitter to find great content to share.
How an email strengthened a community
From Anchorage on the 12th of October 2011, Kieran Mulvaney emailed this to Rachel Weidinger:
“I keep coming to the idea of a weekly or bi-weekly email newsletter, sent to as wide a mailing list of researchers, bloggers, journalists, foundation folks etc as we can pull together, with links to stories, videos etc, summaries of the major stories, and even a little editorializing. And while this may seem inside baseball, another case of the community speaking to itself, it’s a means to an end, a way to a) help ensure that we get sent latest news and info and included in the proverbial loop; and b) help our work be retweeted and forwarded by others with a sympathetic and interested audience.”
It was Kieran’s idea that would, with the visionary help of the Waitt Foundation, become the Tide Report. But we made one significant tweak to Kieran’s proposal: rather than being written for an audience of professional ocean wonks, our primary audience for the Tide Report was this: subscribers who would drive more attention, in measurable ways, to the crisis the ocean is facing.
It’s been nearly three years since we sent our very first Tide Report on June 5, 2012, and, as you can see, much has changed. As Upwell’s flagship missive, it’s the primary way we’ve kept in touch with ocean influencers and run our distributed network campaigns. It was never just an email newsletter, it was so much more.
What is the Tide Report?
The Tide Report’s primary purpose is to drive spikes in online attention to critical ocean issues. It was built to supply influencers who love the ocean with shareable content and easy pathways to amplify that content so that we could transform the conversation about the crisis the ocean faces.
While it was intended as a campaign tool, the Tide Report also served another important purpose - it helped ocean communicators see the work of their peers and understand how they fit into a broader movement. It cultivated a sense of “Team Ocean” and provided the members of that team with models for successful communication.
We’ve written 226 Tide Reports (as of Monday, March 2). Over the years, the style has changed somewhat, but one thing has remained consistent: with each Tide Report, we not only shared the hottest ocean news, but we asked our readers to amplify and share. The purpose was to use the email as a way to help Team Ocean see itself, connect you with the work of your ocean-loving peers, show you what stories, ideas and content get people talking online, and promote sharing, generosity and transparency within our movement. By amplifying the best ocean-y content at the times it mattered most, you showed the power of our collective voice to drive change across issue and organizational boundaries.
Through the Tide Report, Team Ocean amplifies great ocean content.
The impact of the Tide Report as a campaign tool to transform online conversation is reflected in our online conversation analyses like our “State of the Online Conversation” reports about ocean acidification and overfishing. But we rarely talk about the impact of the Tide Report as a community and capacity building tool, so I want to do that today.
Who reads the Tide Report?
While we aren’t at liberty to share the names and email addresses of our readers, we can share some basic stats.
Keep in mind the Tide Report doesn’t fit neatly into any email newsletter box. It lives in the vast gray space between a neighborhood listserv and an advocacy list. Our subscriber list is small in numbers (approximately 1500), but large in reach. We hand-built our list, targeting people who controlled channels where they can influence the public. Many of our subscriptions came out of in-person meetings, one-on-one collaborations, and attendance at meeting and conferences.
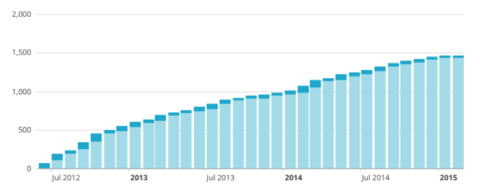
Tide Report list growth shows a consistent increase over time. (Light blue = existing subscribers, dark blue = additional subscribers.
Most of our subscribers (81%) are based in the United States. A significant portion of our readers have subscribed with their work addresses (31% end in .org, 5% in .gov, and 4% in .edu). Many additional subscribers are unaffiliated individuals who just have a passion for the ocean, or ocean conservation professionals that subscribed with their personal email addresses. Below is a graphic showing the breadth and depth of Team Ocean’s representation. All these organizations, institutions, and companies get the Tide Report too!

These are your colleagues on Team Ocean. With this network, we helped amplify attention to what matters.
What that community thought of the Tide Report
We’ve heard from Team Ocean that the Tide Report increased network resiliency, and helped many of the less influential, but just as passionate members of the team make their communications more successful. Last month, we surveyed our Tide Report subscribers, asking them if and how working with Upwell has changed the way they work or has connected them with resources. What we heard reflects the diversity of our readership:
While it’s unlikely that the this scientist’s activity (inspired by our content) directly spiked a conversation, the timely context we provided surely strengthened their communications:
“As a scientist, I am often disconnected with what is happening in the social media sphere, and the Tide Report has been a great way to understand what the general public perceives as current ocean-related issues.”
A secondary goal of the Tide Report was to continuously build social media skills through useful examples:
“Each Tide Report helped me learn about new ocean issues- and I'm not very adept at ocean media, so your guidelines on what to amplify, etc. really helped."
Many of our readers saw that by amplifying the content we suggested and provided, they not only helped draw attention to ocean topics, but they increased engagement on their own channels:
“We use many of the articles and images that come out of the Tide Report for our social media. By doing so, we've seen more engagement within our community members.”
Another secondary goal of the Tide Report was to hold up a mirror to Team Ocean, so its members could see each other and discover new peers:
“I was always surprised at the little nuggets of information I found in the Tide Report and would often find new partners to reach out to.”
We would often hear that reading the Tide Report became part of our readers’ workflow:
“My coworkers and I look forward to the Tide Report. Whenever one of us discovers something new or something catches our eye (every email there is something) we discuss it in our weekly meeting and then pass on the information to guests and volunteers we work with.”
Curation is a resource-intensive process, and we tried to efficiently provide a resource to Team Ocean by sharing the results of our curation widely:
“There's a TON of ocean news that I have to sift through daily, and every time I saw the Tide Report delivered to my inbox, I knew that there'd be some reliable, thought-provoking gems to add to the larger conversation.”
We didn’t target just ocean conservation professionals - many of the influencers on our list are interested in other topics, and we’ve put oceans on their radar.
“I loved the straightforward way the Tide Report showed what your key messages were, and directly asked readers to help amplify them. Additionally, while the ocean was not an area of environmental concern that I was very tuned in to prior to discovering Upwell, it's now something I am much more attuned to when I read the news, discuss conservation issues, and think about my impact on the environment.”
Tide Report engagement and greatest hits
If you’ve been a Tide Report reader for a while, you may remember some of our greatest hits. Recently, I pored through engagement data from our Tide Reports going back to November 2013. Since we usually talk about what resonates with the whole Internet, I thought it might be fun to narrow my lens and look at what resonated the most with our readers.
Here are the top links (measured by number of unique clicks) in Tide Reports since November 2013:
- Upwell’s Buzzfeed article “Why you need to care about the Empty Oceans Act.” - February 7, 2014
- The sea froze so fast that it killed thousands of fish instantly - January 17, 2014
- The link to the job description when we were hiring a Tide Report writer - February 24, 2014
- 23 Fantastic Images Of The Incredibly Weird Things In The Ocean - October 27, 2014
- MBARI’s captivating video about the Black Seadevil anglerfish - November 25, 2014
- The succinct and well-researched Buzzfeed article, 13 Reasons the Ocean Might Never Be The Same - January 17, 2014
- This mind-boggling and upsetting video of a super trawler at work, shared on Facebook by Ocean Defender Hawaii - December 4, 2014
- David Shiffman expressing consternation in Scientific American at the emerging trend of shark riding - March 5, 2014
- Lessons from 2014 from The New York Times’ social media desk - January 23, 2015
- Pacific Standard delves into why Blackfish became so popular - January 24, 2014
These are the Tide Reports that were opened by the largest percentage of subscribers (excluding the first few months of the Tide Report, when open percentages were high but our list was very small). Note that the first three aren’t actually traditional Tide Reports, and are associated with the Upwell Transitions of 2013 and 2015, which goes to show that when you might go away, people pay attention. Numbers eight and nine below (and number 3 above) show that employment opportunities increase engagement. Even if you can’t hire someone, sharing other jobs is generous and a great way to spark interest!
- Not a Tide Report (2013 Survey) - February 7, 2013
- Tide Report: A time of transition - January 28, 2013
- Bittersweet news from the Upwell team - January 12, 2015
- Tide Report: A high-tech solution for plastic pollution? Also: Meet the Mermaid Death Squad - March 28, 2013
- Tide Report: Upwell lessons to share, a hot OA video, NYT sustainable fish debate, and more. - March 5, 2013
- Tide Report: In which we encourage you to NOT get any attention today. - April 19, 2013
- Tide Report: Ocean acidification music video, Grocers reject GMO Salmon, and more - March 21, 2013
- Wanted: Tide Report writer. Anchor-shaped referral bonus! - February 24, 2014
- Tide Report: Upwell’s hiring (again); UNESCO sites to drown; river otter conquers alligator - March 7, 2014
- Tide Report: Ocean education from TED, Sharkinar, CCAMLR, and all the lionfish you can eat. - July 10, 2013
Over time, our Tide Report has experienced unprecedented engagement rates from our readers. Our open rate has hovered consistently around 35% for the past three years, and our click rate has stayed consistent at 9-10%. These rates compare extremely favorably to nonprofit industry averages (13% open rate and 2.9% click rate), as reported by M+R and NTEN in their annual email benchmarks study. Because our list is small, and targeted toward people with high investment in our mission, we’d expect higher engagement rates than donor or action appeals from a traditional nonprofit. It’s still great to see.
What the Tide Report has taught me
So what have I learned from all of this? And what can the Tide Report community do to continue this work after the Tide Report ceases to be?
One of the challenges and biggest lessons I learned in my years writing the Tide Report was how to think about what will resonate. I had to think about what would resonate with the internet at large, a huge grab bag of people - most of whom have a very limited understanding of ocean conservation issues - as well as what would resonate with our readers. I had to inspire our ocean-literate readers to share, but encourage them to share content that would inspire those less familiar with these issues to share too.
Finding that balance was always tough. And sometimes our readers would share the stuff that was the nerdiest and wonkiest, instead of the stuff I had handpicked because it was shareable. Sometimes that totally nerdy thing was going to be a viral hit, and sometimes it just going to get 100 views and disappear. I wanted our readers to understand that we were carefully selecting things that we thought would resonate with a broader audience. One of the critical tools in my practice was our “Why We Choose” list - our curation criteria for what to amplify in the Tide Report. We strongly encourage people to create their own lists, to keep themselves in check and ensure that resources are put into the things that are most likely to succeed.
I also learned that Team Ocean is always eager to learn more. Our Tide Reports that focused on sharing lessons, hosting webinars, reporting back on surveys received incredibly high engagement from our readers. I encourage those on Team Ocean to share, share, share. Write sharing into your grant proposals! Budget time for packaging what you’ve learned. When campaigns or outreach efforts fail, give yourself time to think about why, and don’t be afraid to tell the story publicly. Sharing has been part of Upwell’s brand since day one. Find out how to make it part of yours. Let’s make ocean conservation open source.
Don’t be afraid to ask! I think there’s a culture of fear around asking people to share or retweet your stuff. But how else are you going to get your message out? Our entire model was based on a request to amplify, and while our readers didn’t always amplify everything we sent out, they did amplify the things that resonated with them. But they may not have amplified had we not asked. As we often say, do as Shiffman does (he is the king of “please RT”).
And, finally, when it comes to email lists, small and mighty is better than big and weary. Focus in on who your biggest supporters are. Who’s amplifying your message, and can they be recruited to be part of your team? Cultivate your network in a way that feels like that neighborhood listserv. We send out postcards or care packages to our BFFs. Even if we work on the internet, we live in real life. Let’s not forget that our “lists” are bunches of individual humans, with individual passions, pursuits, fears and regrets.
What have you learned from the Tide Report, and how will you start working differently? Tell us your reactions in the comments.
Big Listening 101: Reliving the Webinar Magic
Over a hundred brave humans signed up for our Big Listening 101 webinar to get an introduction to the concepts and methods that have animated our work here at Upwell for the last three years.
Whether you were able to join us on Thursday or not, we're happy to announce that you can now live, or relive, the magic as you see fit courtesy the Upwell YouTube channel.

For even more Big Listening we recommend the following:
- Peruse the #biglistening hashtag
- Follow our handy Twitter list of Big Listening 101 participants
- Check out (or even contribute to) the Big Listening 101 collaborative notes
If you want to go even deeper, you can give our 2013 Pilot Report a read, or kick the tires on our recent State of the Online Conversation reports on ocean acidification and on overfishing.
What big mission or movement are you listening for? Tell us in the comments or on Twitter by using #biglistening.
So long, and thanks for all the fish!
Big Listening for Overfishing & Fisheries
Today marks the release of our latest, fresh-off-the-docks report on ocean issues through the eyes of the internet.
Overfishing & Fisheries: The State of the Online Conversation

Covering 2012-2014, in this report we draw on millions of social posts to provide data-informed insights for scientists, campaigners, communicators and funders interested in using the web to improve ocean health and abundance.
Take a look, and let us know what you think.
But wait, there's more!
To preview the findings and share them with our beloved Team Ocean (hint: that's you), we're also convening The Overfishinar, a webinar (and so much more) about overfishing.
The Overfishinar will be held today at 11am pacific time. You can register now, or come back to view the recording after its done. (The hashtag to follow the proceedings is, you guessed it, #overfishinar).
UPDATE: You can now watch the Overfishinar!

If you're more of a tl;dr kinda person, you're still in luck:
our handy Overfishing Communications Cheat Sheet summarizes the key tips for effective internetting.

Onwards!